1、IO和NIO

面向流和面向Buffer
传统IO和Java NIO最大的区别是传统的IO是面向流,NIO是面向Buffer
Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
选择器
Java NIO的选择器允许一个单独的线程来 监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道,这些通道里已经有可以处理的输入,或者选择已经准备写入的通道,这种选择机制,使得一个单独的线程很容易来管理多个通道
区别
传统的IO
- socketServer的accept方法是阻塞的;
- 获得连接的顺序是和客户端请求到达服务器的先后顺序相关;
- 适用于一个线程管理一个通道的情况;因为其中的流数据的读取是阻塞的;
- 适合需要管理同时打开不太多的连接,这些连接会发送大量的数据
NIO - 基于事件驱动,当有连接请求,会将此连接注册到多路复用器上(selector);
- 在多路复用器上可以注册监听事件,比如监听accept、read;
- 通过监听,当真正有请求数据时,才来处理数据;
- 会不停的轮询是否有就绪的事件,所以处理顺序和连接请求先后顺序无关,与请求数据到来的先后顺序有关;
- 优势在于一个线程管理多个通道;但是数据的处理将会变得复杂;
- 适合需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据
2、JDK原生NIO程序的问题
JDK 原生也有一套网络应用程序 API,但是存在一系列问题,主要如下:
- NIO 的类库和 API 繁杂,使用麻烦:你需要熟练掌握 Selector、ServerSocketChannel、SocketChannel、ByteBuffer 等。
- 需要具备其他的额外技能做铺垫:例如熟悉 Java 多线程编程,因为 NIO 编程涉及到 Reactor 模式,你必须对多线程和网路编程非常熟悉,才能编写出高质量的 NIO 程序。
- 可靠性能力补齐,开发工作量和难度都非常大:例如客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流的处理等等。NIO 编程的特点是功能开发相对容易,但是可靠性能力补齐工作量和难度都非常大。
- JDK NIO 的 Bug:例如臭名昭著的 Epoll Bug,它会导致 Selector 空轮询,最终导致 CPU 100%。官方声称在 JDK 1.6 版本的 update 18 修复了该问题,但是直到 JDK 1.7 版本该问题仍旧存在,只不过该 Bug 发生概率降低了一些而已,它并没有被根本解决。
3、Netty的介绍
Netty 是一个异步事件驱动的网络应用框架,用于快速开发可维护的高性能服务器和客户端。
Netty 对 JDK 自带的 NIO 的 API 进行了封装,解决了上述问题。Netty的主要特点
1、高性能
- 采用异步非阻塞的IO类库,基于Reactor模式实现,解决了传统同步阻塞IO模式
- TCP接收和发送缓冲区使用直接内存代替堆内存,避免了内存复制,提升了IO读取和写入的性能
- 支持内存池的方式循环利用ByteBuf,避免了频繁插件和销毁ByteBuf带来的性能消耗
- 可配置的IO线程数、TCP参数等,为不同的用户场景提供定制化的调优参数,满足不同的性能场景
- 采用环形数组缓冲区实现无锁化并发编程,代替传统的线程安全或锁。
- 合理使用线程安全容器,原子类,提升系统的并发处理能力
- 关键资源的处理使用单线程串行化的方式,避免多线程并发访问带来的锁竞争和cpu资源消耗
- 通过引用计数法及时地申请释放不再被引用的对象,细粒度的内存管理降低了GC的频率,减少了频繁GC带来的时延增大和CPU损耗
2、可靠性
1、 链路有效监测(心跳和空闲检测)
- 读空闲超时机制
- 写空闲超时机制
2、内存保护机制 - 通过对象引用计数法对Netty的ByteBuf等内置对象进行细粒度的内存申请和释放,对非法的对象引用进行检测和保护
- 通过内存池来重用ByteBuf,节省内存
- 可设置的内存容量上限,包括ByteBuf、线程池线程数
3、优雅停机 - 优雅停机需要设置最大超时时间,如果达到该时间系统还没退出,则通过Kill -9 pid强杀当前线程。
- JVM通过注册的Shutdown Hook拦截到退出信号量,然后执行退出操作
3、可定制性
- 责任链模式:channelPipeline基于责任链模式开发,便于业务逻辑的拦截、定制和扩展
- 基于接口的开发:关键的类库都提供了接口或者抽象类,用户可以自定义实现相关接口
- 提供了大量工厂类,通过重载这些工厂类可以按需创建出用户实现的对象
- 提供大量的系统参数供用户按需设置,增强系统的场景定制
4、可扩展性
可以方便进行应用层协议定制,比如Dubbo、RocketMQ4、Netty的线程模型
对于网络请求一般可以分为两个处理阶段,一是接收请求任务,二是处理网络请求。根据不同阶段处理方式分为以下几种线程模型:1、串行化处理模型
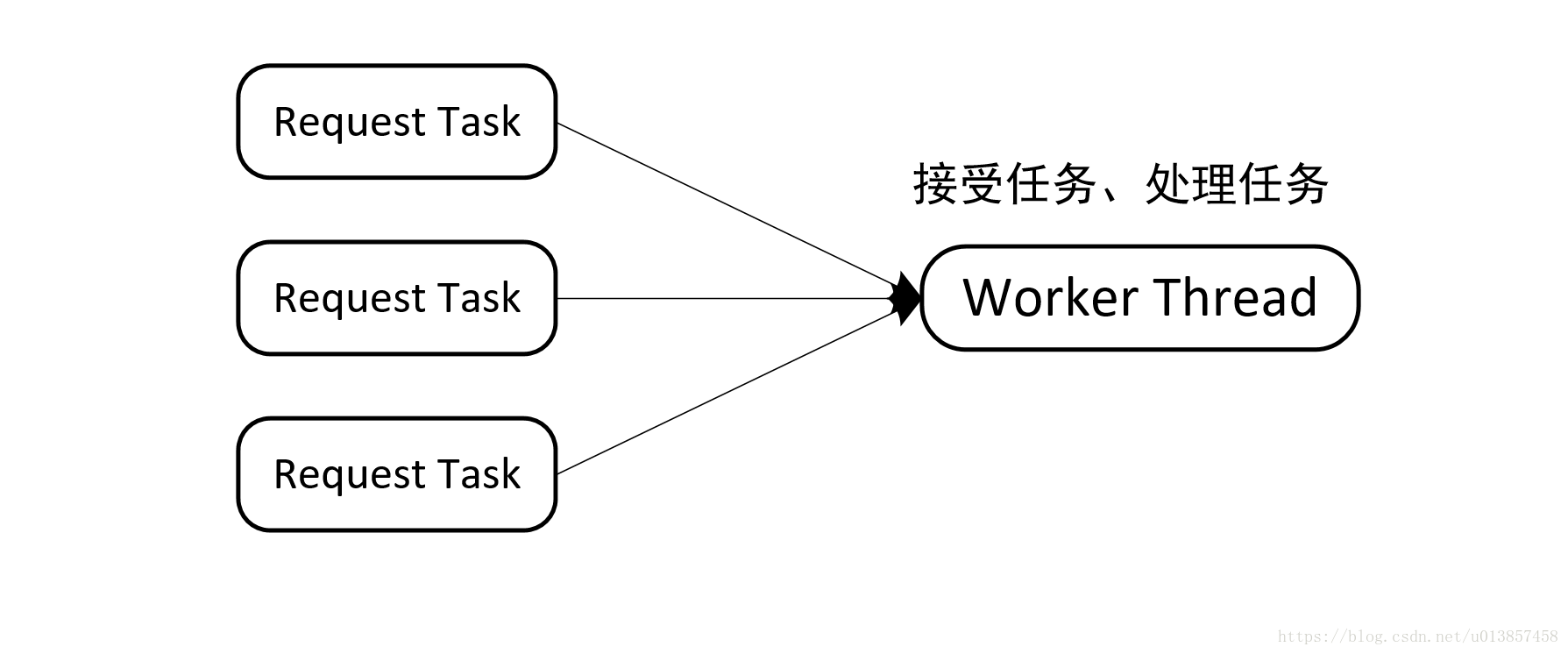
这个模型中用一个线程来处理网络请求连接和任务处理,当worker接受到一个任务之后,就立刻进行处理,也就是说任务接受和任务处理是在同一个worker线程中进行的,没有进行区分。这样做存在一个很大的问题是,必须要等待某个task处理完成之后,才能接受处理下一个task。
因此可以把接收任务和处理任务两个阶段分开处理,一个线程接收任务,放入任务队列,另外的线程异步处理任务队列中的任务。2、并行化处理模型

由于任务处理一般比较缓慢,会导致任务队列中任务积压长时间得不到处理,这时可以使用线程池来处理。可以通过为每个线程维护一个任务队列来改进这种模型。3、Netty具体线程模型

1、如何理解NioEventLoop和NioEventLoopGroup
- NioEventLoop实际上就是工作线程,可以直接理解为一个线程。NioEventLoopGroup是一个线程池,线程池中的线程就是NioEventLoop。
- 实际上bossGroup中有多个NioEventLoop线程,每个NioEventLoop绑定一个端口,也就是说,如果程序只需要监听1个端口的话,bossGroup里面只需要有一个NioEventLoop线程就行了。
2、每个NioEventLoop都绑定了一个Selector,所以在Netty的线程模型中,是由多个Selecotr在监听IO就绪事件。而Channel注册到Selector。
3、一个Channel绑定一个NioEventLoop,相当于一个连接绑定一个线程,这个连接所有的ChannelHandler都是在一个线程中执行的,避免了多线程干扰。更重要的是ChannelPipline链表必须严格按照顺序执行的。单线程的设计能够保证ChannelHandler的顺序执行。
4、一个NioEventLoop的selector可以被多个Channel注册,也就是说多个Channel共享一个EventLoop。EventLoop的Selecctor对这些Channel进行检查。5、Netty工作原理
1、server端工作原理
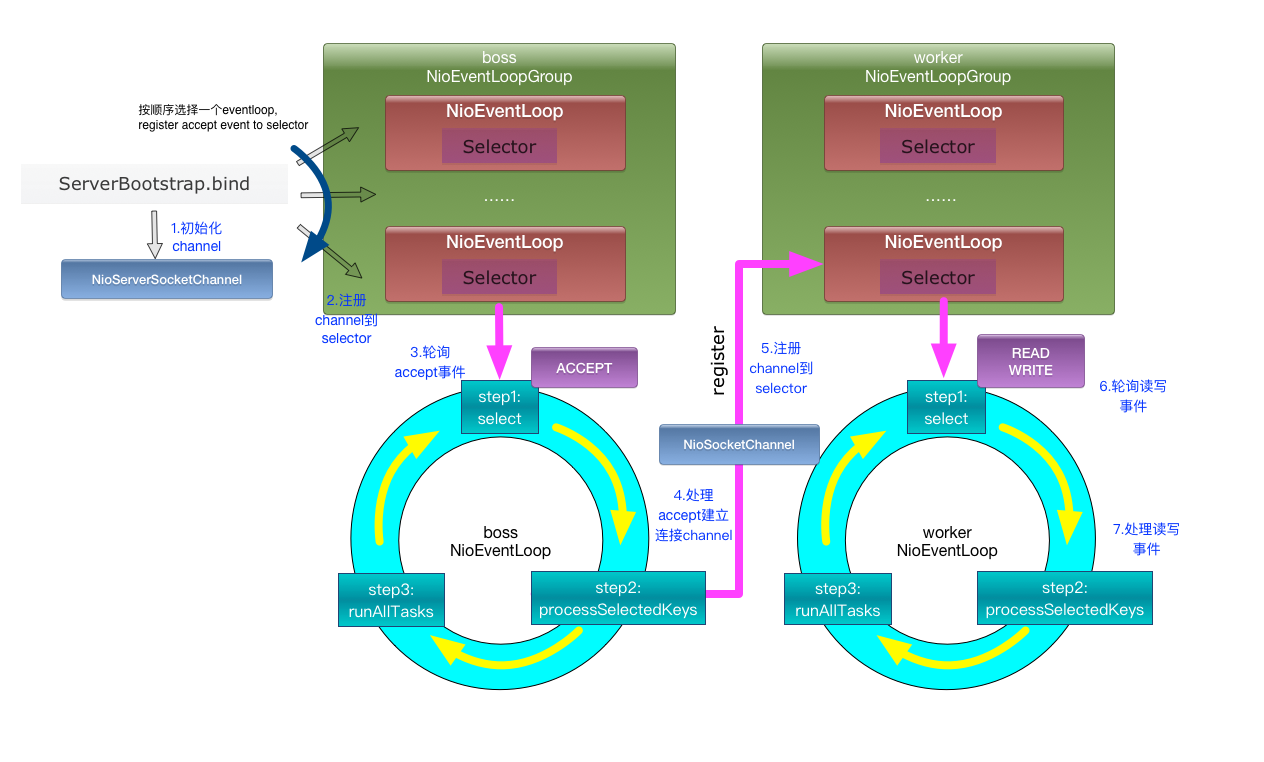
server端启动时绑定本地某个端口,将自己NioServerSocketChannel注册到某个boss NioEventLoop的selector上。
server端包含1个boss NioEventLoopGroup和1个worker NioEventLoopGroup,NioEventLoopGroup相当于1个事件循环组,这个组里包含多个事件循环NioEventLoop,每个NioEventLoop包含1个selector和1个事件循环线程。
每个boss NioEventLoop循环执行的任务包含3步:
- 轮询accept事件;
- 处理io任务,即accept事件,与client建立连接,生成NioSocketChannel,并将NioSocketChannel注册到某个worker NioEventLoop的selector上;
- 处理任务队列中的任务,runAllTasks。任务队列中的任务包括用户调用eventloop.execute或schedule执行的任务,或者其它线程提交到该eventloop的任务。
每个worker NioEventLoop循环执行的任务包含3步: - 轮询read、write事件;
- 处理io任务,即read、write事件,在NioSocketChannel可读、可写事件发生时进行处理;
- 处理任务队列中的任务,runAllTasks。
2、client端工作原理
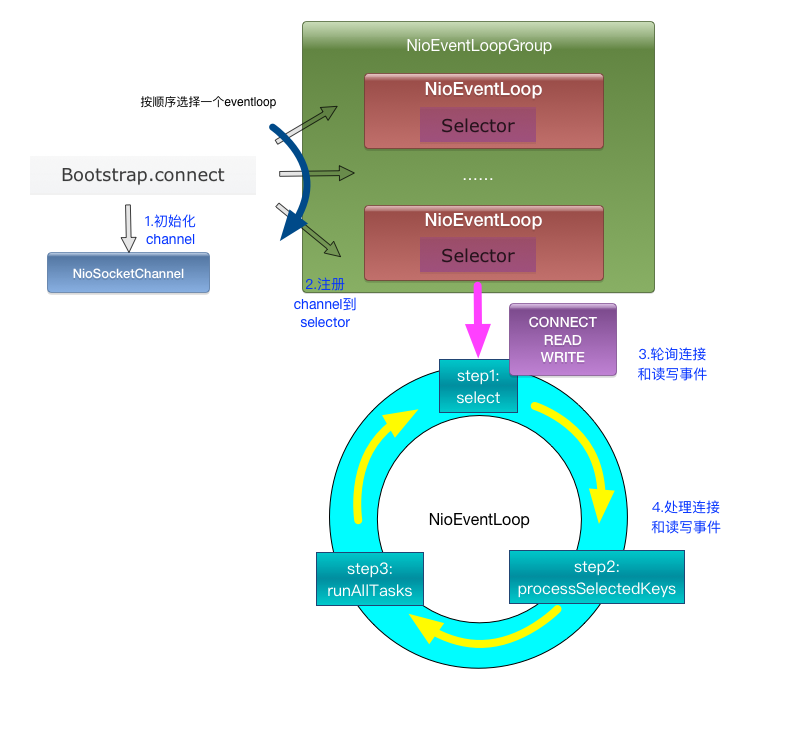
client端启动时connect到server,建立NioSocketChannel,并注册到某个NioEventLoop的selector上。
client端只包含1个NioEventLoopGroup,每个NioEventLoop循环执行的任务包含3步: - 轮询connect、read、write事件;
- 处理io任务,即connect、read、write事件,在NioSocketChannel连接建立、可读、可写事件发生时进行处理;
- 处理非io任务,runAllTasks。
6、netty的启动
1、服务端启动流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class NettyServer {
public static void main(String[] args) {
NioEventLoopGroup bossGroup = new NioEventLoopGroup();
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap
.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
protected void initChannel(NioSocketChannel ch) {
}
});
serverBootstrap.bind(8000);
}
} - 首先创建了两个NioEventLoopGroup,这两个对象可以看做是传统IO编程模型的两大线程组,bossGroup表示监听端口,accept 新连接的线程组,workerGroup表示处理每一条连接的数据读写的线程组。
- 接下来创建了一个引导类 ServerBootstrap,这个类将引导我们进行服务端的启动工作,直接new出来开搞。
- 通过.group(bossGroup, workerGroup)给引导类配置两大线程组,这个引导类的线程模型也就定型了。
- 然后指定服务端的 IO 模型为NIO,我们通过.channel(NioServerSocketChannel.class)来指定 IO 模型。
- 最后我们调用childHandler()方法,给这个引导类创建一个ChannelInitializer,这里主要就是定义后续每条连接的数据读写,业务处理逻辑。ChannelInitializer这个类中,我们注意到有一个泛型参数NioSocketChannel,这个类是 Netty 对 NIO 类型的连接的抽象,而我们前面NioServerSocketChannel也是对 NIO 类型的连接的抽象,NioServerSocketChannel和NioSocketChannel的概念可以和 BIO 编程模型中的ServerSocket以及Socket两个概念对应上
总结:创建一个引导类,然后给他指定线程模型,IO模型,连接读写处理逻辑,绑定端口之后,服务端就启动起来了。2、客户端启动流程
对于客户端的启动来说,和服务端的启动类似,依然需要线程模型、IO 模型,以及 IO 业务处理逻辑三大参数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public class NettyClient {
public static void main(String[] args) {
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
Bootstrap bootstrap = new Bootstrap();
bootstrap
// 1.指定线程模型
.group(workerGroup)
// 2.指定 IO 类型为 NIO
.channel(NioSocketChannel.class)
// 3.IO 处理逻辑
.handler(new ChannelInitializer<SocketChannel>() {
public void initChannel(SocketChannel ch) {
}
});
// 4.建立连接
bootstrap.connect("juejin.im", 80).addListener(future -> {
if (future.isSuccess()) {
System.out.println("连接成功!");
} else {
System.err.println("连接失败!");
}
});
}
} - 首先,与服务端的启动一样,需要给它指定线程模型,驱动着连接的数据读写
- 然后指定 IO 模型为 NioSocketChannel,表示 IO 模型为 NIO
- 接着给引导类指定一个 handler,这里主要就是定义连接的业务处理逻辑
- 配置完线程模型、IO 模型、业务处理逻辑之后,调用 connect 方法进行连接,可以看到 connect 方法有两个参数,第一个参数可以填写 IP 或者域名,第二个参数填写的是端口号,由于 connect 方法返回的是一个 Future,也就是说这个方是异步的,我们通过 addListener 方法可以监听到连接是否成功,进而打印出连接信息
总结:创建一个引导类,然后给他指定线程模型,IO 模型,连接读写处理逻辑,连接上特定主机和端口,客户端就启动起来了7、ByteBuf
ByteBuf是一个节点容器,里面数据包括三部分: - 已经丢弃的数据,这部分数据是无效的
- 可读字节,这部分数据是ByteBuf的主体
- 可写字节
这三段数据被两个指针给划分出来,读指针、写指针。
ByteBuf 本质上就是,它引用了一段内存,这段内存可以是堆内也可以是堆外的,然后用引用计数来控制这段内存是否需要被释放,使用读写指针来控制对 ByteBuf 的读写,可以理解为是外观模式的一种使用
基于读写指针和容量、最大可扩容容量,衍生出一系列的读写方法,要注意 read/write 与 get/set 的区别
多个 ByteBuf 可以引用同一段内存,通过引用计数来控制内存的释放,遵循谁 retain() 谁 release() 的原则ByteBuf和ByteBuffer的区别
- 可扩展到用户定义的buffer类型中
- 通过内置的复合buffer类型实现透明的零拷贝(zero-copy)
- 容量可以根据需要扩展
- 切换读写模式不需要调用ByteBuffer.flip()方法
- 读写采用不同的索引
- 支持方法链接调用
- 支持引用计数
- 支持池技术(比如:线程池、数据库连接池)
ByteBuf和设计模式
1、ByteBufAllocator - 抽象工厂模式
在Netty的世界里,ByteBuf实例通常应该由ByteBufAllocator来创建。2、CompositeByteBuf - 组合模式
CompositeByteBuf可以让我们把多个ByteBuf当成一个大Buf来处理,ByteBufAllocator提供了compositeBuffer()工厂方法来创建CompositeByteBuf。CompositeByteBuf的实现使用了组合模式3、ByteBufInputStream - 适配器模式
ByteBufInputStream使用适配器模式,使我们可以把ByteBuf当做Java的InputStream来使用。同理,ByteBufOutputStream允许我们把ByteBuf当做OutputStream来使用。4、ReadOnlyByteBuf - 装饰器模式
ReadOnlyByteBuf用适配器模式把一个ByteBuf变为只读,ReadOnlyByteBuf通过调用Unpooled.unmodifiableBuffer(ByteBuf)方法获得: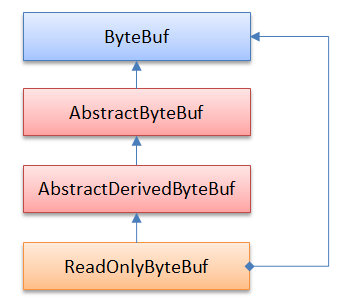
5、ByteBuf - 工厂方法模式
我们很少需要直接通过构造函数来创建ByteBuf实例,而是通过Allocator来创建。从装饰器模式可以看出另外一种获得ByteBuf的方式是调用ByteBuf的工厂方法,比如:
- ByteBuf#duplicate()
- ByteBuf#slice()
9、channelHandler
channelHandler在只会对感兴趣的事件进行拦截和处理,Servlet的Filter过滤器,负责对IO事件或者IO操作进行拦截和处理,它可以选择性地拦截和处理自己感兴趣的事件,也可以透传和终止事件的传递。
pipeline与channelHandler它们通过责任链设计模式来组织代码逻辑,并且支持逻辑的动态添加和删除。
ChannelHandler 有两大子接口: - 第一个子接口是 ChannelInboundHandler,从字面意思也可以猜到,他是处理读数据的逻辑
- 第二个子接口 ChannelOutBoundHandler 是处理写数据的逻辑
这两个子接口分别有对应的默认实现,ChannelInboundHandlerAdapter,和 ChanneloutBoundHandlerAdapter,它们分别实现了两大接口的所有功能,默认情况下会把读写事件传播到下一个 handler。事件的传播
AbstractChannel直接调用了Pipeline的write()方法,因为write是个outbound事件,所以DefaultChannelPipeline直接找到tail部分的context,调用其write()方法:
context的write()方法沿着context链往前找,直至找到一个outbound类型的context为止,然后调用其invokeWrite()方法:
10、NioEventLoop
NioEventLoop除了要处理IO事件,还有主要:
- 非IO操作的系统Task
- 定时任务
非IO操作和IO操作各占默认值50%,底层使用Selector(多路复用器)
Selector BUG出现的原因
若Selector的轮询结果为空,也没有wakeup或新消息处理,则发生空轮询,CPU使用率100%,Netty的解决办法
- 对Selector的select操作周期进行统计,每完成一次空的select操作进行一次计数,
- 若在某个周期内连续发生N次空轮询,则触发了epoll死循环bug。
- 重建Selector,判断是否是其他线程发起的重建请求,若不是则将原SocketChannel从旧的Selector上去除注册,重新注册到新的Selector上,并将原来的Selector关闭。
11、通信协议编解码
通信协议是为了服务端与客户端交互,双方协商出来的满足一定规则的二进制格式
- 客户端把一个Java对象按照通信协议转换成二进制数据包
- 把二进制数据包发送到服务端,数据的传输油TCP/IP协议负责
- 服务端收到二进制数据包后,按照通信协议,包装成Java对象。
通信协议的设计 - 魔数,作用:能够在第一时间识别出这个数据包是不是遵循自定义协议的,也就是无效数据包,为了安全考虑可以直接关闭连接以节省资源。
- 版本号
- 序列化算法
- 指令
- 数据长度
- 数据
12、Netty内存池和对象池
1、内存池是指为了实现内存池的功能,设计一个内存结构Chunk,其内部管理着一个大块的连续内存区域,将这个内存区域切分成均等的大小,每一个大小称之为一个Page。将从内存池中申请内存的动作映射为从Chunk中申请一定数量Page。为了方便计算和申请Page,Chunk内部采用完全二叉树的方式对Page进行管理。
2、对象池是指Recycler整个对象池的核心实现由ThreadLocal和Stack及WrakOrderQueue构成,接着来看Stack和WrakOrderQueue的具体实现,最后概括整体实现。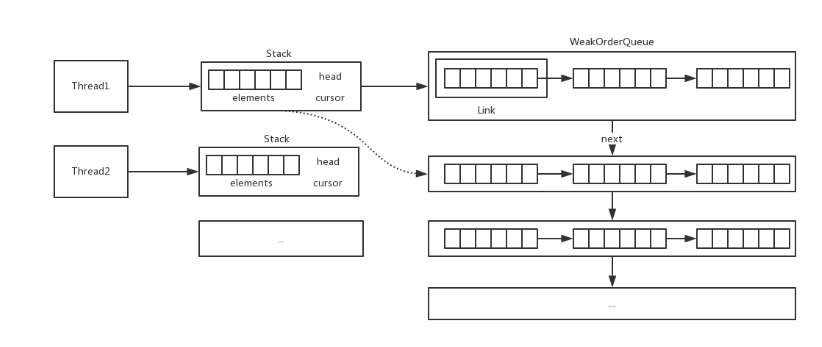
整个设计上核心的几点: - Stack相当于是一级缓存,同一个线程内的使用和回收都将使用一个Stack
- 每个线程都会有一个自己对应的Stack,如果回收的线程不是Stack的线程,将元素放入到Queue中
- 所有的Queue组合成一个链表,Stack可以从这些链表中回收元素(实现了多线程之间共享回收的实例)
13、心跳与空闲检测
连接假死的现象是:在某一端(服务端或者客户端)看来,底层的 TCP 连接已经断开了,但是应用程序并没有捕获到,因此会认为这条连接仍然是存在的,从 TCP 层面来说,只有收到四次握手数据包或者一个 RST 数据包,连接的状态才表示已断开。
假死导致两个问题 - 对于服务端,每条连接都会耗费cpu和内存资源,大量假死的连接会耗光服务器的资源
- 对于客户端,假死会造成发送数据超时,影响用户体验
通常,连接假死由以下几个原因造成的 - 应用程序出现线程堵塞,无法进行数据的读写。
- 客户端或者服务端网络相关的设备出现故障,比如网卡,机房故障。
- 公网丢包。公网环境相对内网而言,非常容易出现丢包,网络抖动等现象,如果在一段时间内用户接入的网络连续出现丢包现象,那么对客户端来说数据一直发送不出去,而服务端也是一直收不到客户端来的数据,连接就一直耗着
服务端空闲检测
- 如果能一直收到客户端发来的数据,那么可以说明这条连接还是活的,因此,服务端对于连接假死的应对策略就是空闲检测。
- 简化一下,我们的服务端只需要检测一段时间内,是否收到过客户端发来的数据即可,Netty 自带的 IdleStateHandler 就可以实现这个功能。
IdleStateHandler 的构造函数有四个参数,其中第一个表示读空闲时间,指的是在这段时间内如果没有数据读到,就表示连接假死;第二个是写空闲时间,指的是 在这段时间如果没有写数据,就表示连接假死;第三个参数是读写空闲时间,表示在这段时间内如果没有产生数据读或者写,就表示连接假死。写空闲和读写空闲为0,表示我们不关心者两类条件;最后一个参数表示时间单位。在我们的例子中,表示的是:如果 15 秒内没有读到数据,就表示连接假死。
在一段时间之内没有读到客户端的数据,是否一定能判断连接假死呢?并不能为了防止服务端误判,我们还需要在客户端做点什么。客户端定时心跳
服务端在一段时间内没有收到客户端的数据有两种情况 - 连接假死
- 非假死确实没数据发
所以我们要排除第二种情况就能保证连接自然就是假死的,定期发送心跳到服务端
实现了每隔 5 秒,向服务端发送一个心跳数据包,这个时间段通常要比服务端的空闲检测时间的一半要短一些,我们这里直接定义为空闲检测时间的三分之一,主要是为了排除公网偶发的秒级抖动。
为了排除是否是因为服务端在非假死状态下确实没有发送数据,服务端也要定期发送心跳给客户端。14、拆包粘包理论与解决
TCP是个“流”协议,所谓流,就是没有界限的一串数据。TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行包的划分,所以在业务上认为,一个完整的包可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的TCP粘包和拆包的问题。
解决方法 - 解决思路是在封装自己的包协议:包=包内容长度(4byte)+包内容
- 对于粘包问题先读出包头即包体长度n,然后再读取长度为n的包内容,这样数据包之间的边界就清楚了。
- 对于断包问题先读出包头即包体长度n,由于此次读取的缓存区长度小于n,这时候就需要先缓存这部分的内容,等待下次read事件来时拼接起来形成完整的数据包。
15、Netty 自带的拆包器
1、固定长度的拆包器 FixedLengthFrameDecoder
如果你的应用层协议非常简单,每个数据包的长度都是固定的,比如 100,那么只需要把这个拆包器加到 pipeline 中,Netty 会把一个个长度为 100 的数据包 (ByteBuf) 传递到下一个 channelHandler。2、行拆包器 LineBasedFrameDecoder
从字面意思来看,发送端发送数据包的时候,每个数据包之间以换行符作为分隔,接收端通过 LineBasedFrameDecoder 将粘过的 ByteBuf 拆分成一个个完整的应用层数据包。3、分隔符拆包器 DelimiterBasedFrameDecoder
DelimiterBasedFrameDecoder 是行拆包器的通用版本,只不过我们可以自定义分隔符。4、基于长度域拆包器 LengthFieldBasedFrameDecoder
这种拆包器是最通用的一种拆包器,只要你的自定义协议中包含长度域字段,均可以使用这个拆包器来实现应用层拆包。16、预留问题
默认情况下,Netty服务端启动多少个线程?何时启动?
Netty是如何解决jdk空轮询bug?
Netty如何保证异步串行无锁?
Netty是在哪里检测有新连接接入的?
答:Boss线程通过服务端Channel绑定的Selector轮询OP_ACCEPT事件,通过JDK底层Channel的accept()方法获取JDK底层SocketChannel创建新连接
新连接是怎样注册到NioEventLoop线程的?
答:Worker线程调用Chooser的next()方法选择获取NioEventLoop绑定到客户端Channel,使用doRegister()方法将新连接注册到NioEventLoop的Selector上面
Netty是如何判断ChannelHandler类型的?
对于ChannelHandler的添加应遵循什么顺序?
用户手动触发事件传播,不同触发方式的区别?
Netty内存类别有哪些?
如何减少多线程内存分配之间的竞争?
不同大小的内存是如何进行分配的?
解码器抽象的解码过程是什么样的?
Netty里面有哪些拆箱即用的解码器?
如何把对象变成字节流,最终写到Socket底层?
Netty内存泄漏问题怎么解决?
