DNS解析步骤:
客户端先检查本地的 DNS 缓存,查看是否存在并且是存活着的该域名的地址记录。DNS 是以存活时间(Time to Live,TTL)来衡量缓存的有效情况的,所以,如果某个域名改变了 IP 地址,DNS 服务器并没有任何机制去通知缓存了该地址的机器去更新或者失效掉缓存,只能依靠 TTL 超期后的重新获取来保证一致性。后续每一级 DNS 查询的过程都会有类似的缓存查询操作,再遇到时笔者就不重复叙述了。
客户端将地址发送给本机操作系统中配置的本地 DNS(Local DNS),这个本地 DNS 服务器可以由用户手工设置,也可以在 DHCP 分配时或者在拨号时从 PPP 服务器中自动获取到。
本地 DNS 收到查询请求后,会按照 “是否有
www.icyfenix.com.cn的权威服务器” →“是否有icyfenix.com.cn的权威服务器” →“是否有com.cn的权威服务器”→“是否有cn的权威服务器”的顺序,依次查询自己的地址记录,如果都没有查询到,就会一直找到最后点号代表的根域名服务器为止。这个步骤里涉及了两个重要名词:- 权威域名服务器(Authoritative DNS):是指负责翻译特定域名的 DNS 服务器,“权威”意味着这个域名应该翻译出怎样的结果是由它来决定的。DNS 翻译域名时无需像查电话本一样刻板地一对一翻译,根据来访机器、网络链路、服务内容等各种信息,可以玩出很多花样,权威 DNS 的灵活应用,在后面的内容分发网络、服务发现等章节都还会有所涉及。
- 根域名服务器(Root DNS)是指固定的、无需查询的顶级域名(Top-Level Domain)服务器,可以默认为它们已内置在操作系统代码之中。全世界一共有 13 组根域名服务器(注意并不是 13 台,每一组根域名都通过任播的方式建立了一大群镜像,根据维基百科的数据,迄今已经超过 1000 台根域名服务器的镜像了)。13 这个数字是由于 DNS 主要采用 UDP 传输协议(在需要稳定性保证的时候也可以采用 TCP)来进行数据交换,未分片的 UDP 数据包在 IPv4 下最大有效值为 512 字节,最多可以存放 13 组地址记录,由此而来的限制。
现在假设本地 DNS 是全新的,上面不存在任何域名的权威服务器记录,所以当 DNS 查询请求按步骤 3 的顺序一直查到根域名服务器之后,它将会得到“
cn的权威服务器”的地址记录,然后通过“cn的权威服务器”,得到“com.cn的权威服务器”的地址记录,以此类推,最后找到能够解释www.icyfenix.com.cn的权威服务器地址。通过“
www.icyfenix.com.cn的权威服务器”,查询www.icyfenix.com.cn的地址记录,地址记录并不一定就是指 IP 地址,在 RFC 规范中有定义的地址记录类型已经多达数十种,譬如 IPv4 下的 IP 地址为 A 记录,IPv6 下的 AAAA 记录、主机别名 CNAME 记录,等等。
每种记录类型中还可以包括多条记录,以一个域名下配置多条不同的 A 记录为例,此时权威服务器可以根据自己的策略来进行选择,典型的应用是智能线路:根据访问者所处的不同地区(譬如华北、华南、东北)、不同服务商(譬如电信、联通、移动)等因素来确定返回最合适的 A 记录,将访问者路由到最合适的数据中心,达到智能加速的目的。
专门有一种被称为“DNS 预取”(DNS Prefetching)的前端优化手段用来避免这类问题:如果网站后续要使用来自于其他域的资源,那就在网页加载时生成一个 link 请求,促使浏览器提前对该域名进行预解释,譬如下面代码所示:
1 | <link rel="dns-prefetch" href="//domain.not-icyfenx.cn"> |
表 4-1 OSI 七层模型
| 层 | 数据单元 | 功能 | |
|---|---|---|---|
| 7 | 应用层 Application Layer | 数据 Data | 提供为应用软件提供服务的接口,用于与其他应用软件之间的通信。典型协议:HTTP、HTTPS、FTP、Telnet、SSH、SMTP、POP3 等 |
| 6 | 表达层 Presentation Layer | 数据 Data | 把数据转换为能与接收者的系统格式兼容并适合传输的格式。 |
| 5 | 会话层 Session Layer | 数据 Data | 负责在数据传输中设置和维护计算机网络中两台计算机之间的通信连接。 |
| 4 | 传输层 Transport Layer | 数据段 Segments | 把传输表头加至数据以形成数据包。传输表头包含了所使用的协议等发送信息。典型协议:TCP、UDP、RDP、SCTP、FCP 等 |
| 3 | 网络层 Network Layer | 数据包 Packets | 决定数据的传输路径选择和转发,将网络表头附加至数据段后以形成报文(即数据包)。典型协议:IPv4/IPv6、IGMP、ICMP、EGP、RIP 等 |
| 2 | 数据链路层 Data Link Layer | 数据帧 Frame | 负责点对点的网络寻址、错误侦测和纠错。当表头和表尾被附加至数据包后,就形成数据帧(Frame)。典型协议:WiFi(802.11)、Ethernet(802.3)、PPP 等。 |
| 1 | 物理层 Physical Layer | 比特流 Bit | 在局域网上传送数据帧,它负责管理电脑通信设备和网络媒体之间的互通。包括了针脚、电压、线缆规范、集线器、中继器、网卡、主机接口卡等。 |
负载均衡
数据链路层负载均衡
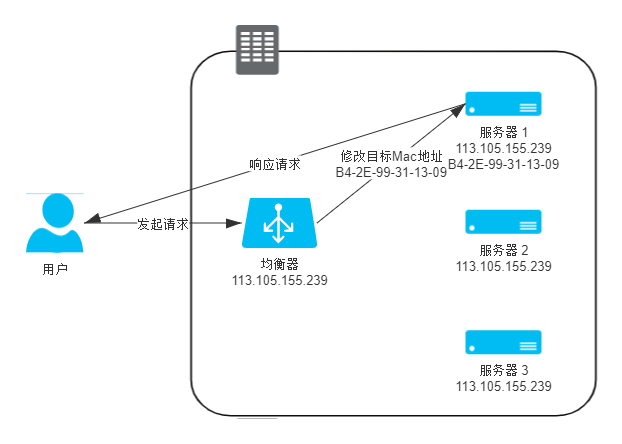
数据链路层负载均衡所做的工作,是修改请求的数据帧中的 MAC 目标地址,让用户原本是发送给负载均衡器的请求的数据帧,被二层交换机根据新的 MAC 目标地址转发到服务器集群中对应的服务器(后文称为“真实服务器”,Real Server)的网卡上,这样真实服务器就获得了一个原本目标并不是发送给它的数据帧。
由于二层负载均衡器在转发请求过程中只修改了帧的 MAC 目标地址,不涉及更上层协议(没有修改 Payload 的数据),所以在更上层(第三层)看来,所有数据都是未曾被改变过的。由于第三层的数据包,即 IP 数据包中包含了源(客户端)和目标(均衡器)的 IP 地址,只有真实服务器保证自己的 IP 地址与数据包中的目标 IP 地址一致,这个数据包才能被正确处理。因此,使用这种负载均衡模式时,需要把真实物理服务器集群所有机器的虚拟 IP 地址(Virtual IP Address,VIP)配置成与负载均衡器的虚拟 IP 一样,这样经均衡器转发后的数据包就能在真实服务器中顺利地使用。也正是因为实际处理请求的真实物理服务器 IP 和数据请求中的目的 IP 是一致的,所以响应结果就不再需要通过负载均衡服务器进行地址交换,可将响应结果的数据包直接从真实服务器返回给用户的客户端,避免负载均衡器网卡带宽成为瓶颈,因此数据链路层的负载均衡效率是相当高的。整个请求到响应的过程如图 4-8 所示。
网络层负载均衡
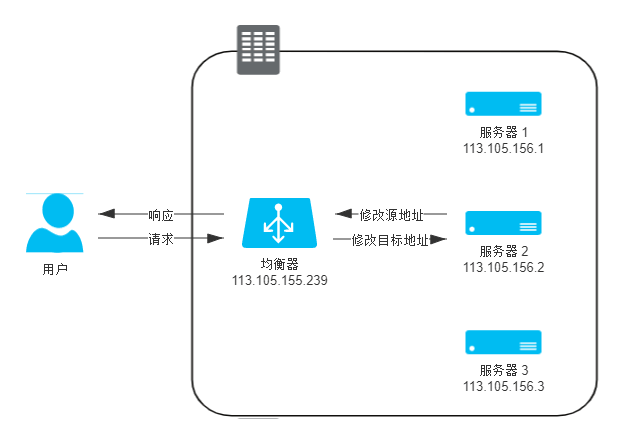
到达网络层,修改目标IP
缺点
真实服务器直接将应答包返回客户端,客户端不认识该 IP,无法正常处理应答。
因此,只能让应答流量回到负载均衡,由负载均衡把应答包的源 IP 改回自己的 IP,再发给客户端。
这种负载均衡的模式被称为 NAT 模式,NAT 模式的负载均衡器运维起来十分简单,只要机器将自己的网关地址设置为均衡器地址,就无须再进行任何额外设置了。此模式从请求到响应的过程如
在流量压力比较大的时候,NAT 模式的负载均衡会带来较大的性能损失,比起直接路由和 IP 隧道模式,甚至会出现数量级上的下降。
应用层负载均衡
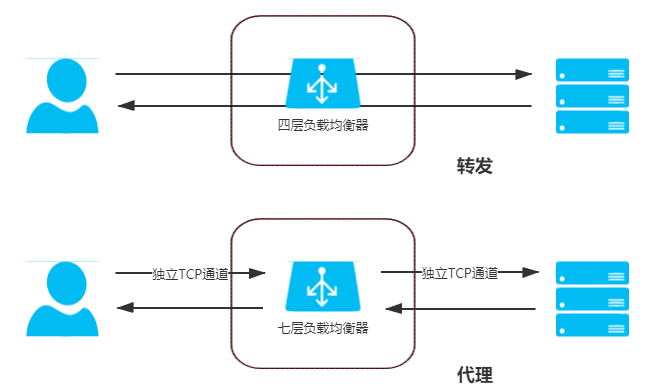
前四层负载均衡工作模式都属于“转发”,即直接将承载着 TCP 报文的底层数据格式(IP 数据包或以太网帧)转发到真实服务器上,此时客户端到响应请求的真实服务器维持着同一条 TCP 通道。但工作在四层之后的负载均衡模式就无法再进行转发了,只能进行代理,此时真实服务器、负载均衡器、客户端三者之间由两条独立的 TCP 通道来维持通信,转发与代理的区别如图 4-11 所示。
应用层负载均衡作用
- 前面介绍 CDN 应用时,所有 CDN 可以做的缓存方面的工作(就是除去 CDN 根据物理位置就近返回这种优化链路的工作外),七层均衡器全都可以实现,譬如静态资源缓存、协议升级、安全防护、访问控制,等等。
- 七层均衡器可以实现更智能化的路由。譬如,根据 Session 路由,以实现亲和性的集群;根据 URL 路由,实现专职化服务(此时就相当于网关的职责);甚至根据用户身份路由,实现对部分用户的特殊服务(如某些站点的贵宾服务器),等等。
- 某些安全攻击可以由七层均衡器来抵御,譬如一种常见的 DDoS 手段是 SYN Flood 攻击,即攻击者控制众多客户端,使用虚假 IP 地址对同一目标大量发送 SYN 报文。从技术原理上看,由于四层均衡器无法感知上层协议的内容,这些 SYN 攻击都会被转发到后端的真实服务器上;而七层均衡器下这些 SYN 攻击自然在负载均衡设备上就被过滤掉,不会影响到后面服务器的正常运行。类似地,可以在七层均衡器上设定多种策略,譬如过滤特定报文,以防御如 SQL 注入等应用层面的特定攻击手段。
- 很多微服务架构的系统中,链路治理措施都需要在七层中进行,譬如服务降级、熔断、异常注入,等等。譬如,一台服务器只有出现物理层面或者系统层面的故障,导致无法应答 TCP 请求才能被四层均衡器所感知,进而剔除出服务集群,如果一台服务器能够应答,只是一直在报 500 错,那四层均衡器对此是完全无能力的,只能由七层均衡器来解决。
均衡策略与实现
- 轮循均衡(Round Robin):每一次来自网络的请求轮流分配给内部中的服务器,从 1 至 N 然后重新开始。此种均衡算法适合于集群中的所有服务器都有相同的软硬件配置并且平均服务请求相对均衡的情况。
- 权重轮循均衡(Weighted Round Robin):根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。譬如:服务器 A 的权值被设计成 1,B 的权值是 3,C 的权值是 6,则服务器 A、B、C 将分别接收到 10%、30%、60%的服务请求。此种均衡算法能确保高性能的服务器得到更多的使用率,避免低性能的服务器负载过重。
- 随机均衡(Random):把来自客户端的请求随机分配给内部中的多个服务器,在数据足够大的场景下能达到相对均衡的分布。
- 权重随机均衡(Weighted Random):此种均衡算法类似于权重轮循算法,不过在分配处理请求时是个随机选择的过程。
- 一致性哈希均衡(Consistency Hash):根据请求中某一些数据(可以是 MAC、IP 地址,也可以是更上层协议中的某些参数信息)作为特征值来计算需要落在的节点上,算法一般会保证同一个特征值每次都一定落在相同的服务器上。一致性的意思是保证当服务集群某个真实服务器出现故障,只影响该服务器的哈希,而不会导致整个服务集群的哈希键值重新分布。
- 响应速度均衡(Response Time):负载均衡设备对内部各服务器发出一个探测请求(例如 Ping),然后根据内部中各服务器对探测请求的最快响应时间来决定哪一台服务器来响应客户端的服务请求。此种均衡算法能较好的反映服务器的当前运行状态,但这最快响应时间仅仅指的是负载均衡设备与服务器间的最快响应时间,而不是客户端与服务器间的最快响应时间。
- 最少连接数均衡(Least Connection):客户端的每一次请求服务在服务器停留的时间可能会有较大的差异,随着工作时间加长,如果采用简单的轮循或随机均衡算法,每一台服务器上的连接进程可能会产生极大的不平衡,并没有达到真正的负载均衡。最少连接数均衡算法对内部中需负载的每一台服务器都有一个数据记录,记录当前该服务器正在处理的连接数量,当有新的服务连接请求时,将把当前请求分配给连接数最少的服务器,使均衡更加符合实际情况,负载更加均衡。此种均衡策略适合长时处理的请求服务,如 FTP 传输。
